This article showcases a Proof of Concept (PoC) where the end result is a fully operational Kubernetes cluster hosting a sample full-stack Django application, along with tools to manage its CI/CD and observability tasks.
You can find the complete setup on instructions in the GitHub repository.
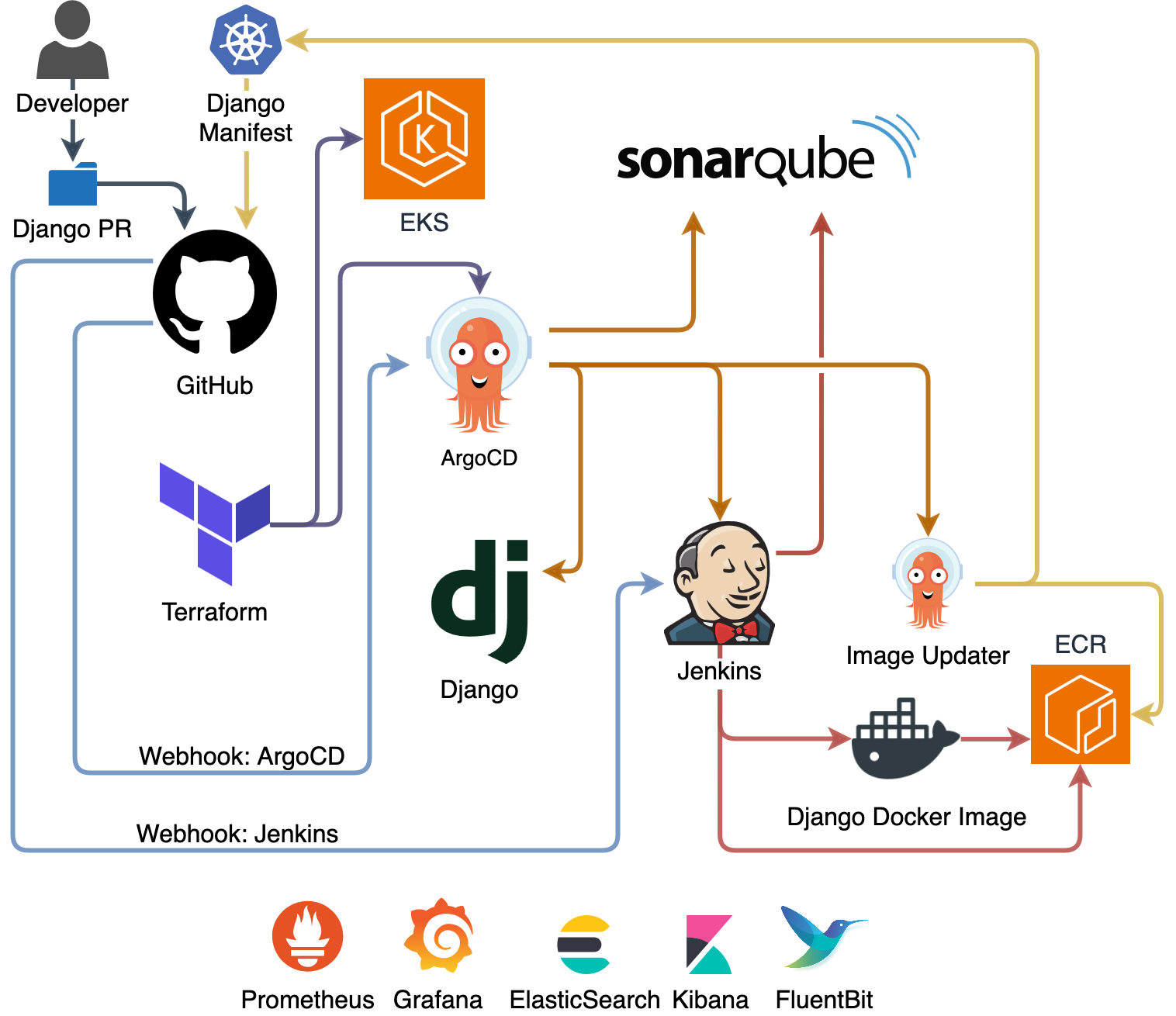
In this project, all applications will launch and operate seamlessly after executing this command from the project home path:
terraform -chdir="terraform/01-eks-cluster/" apply -auto-approve && \
terraform -chdir="terraform/02-argocd/" apply -auto-approve
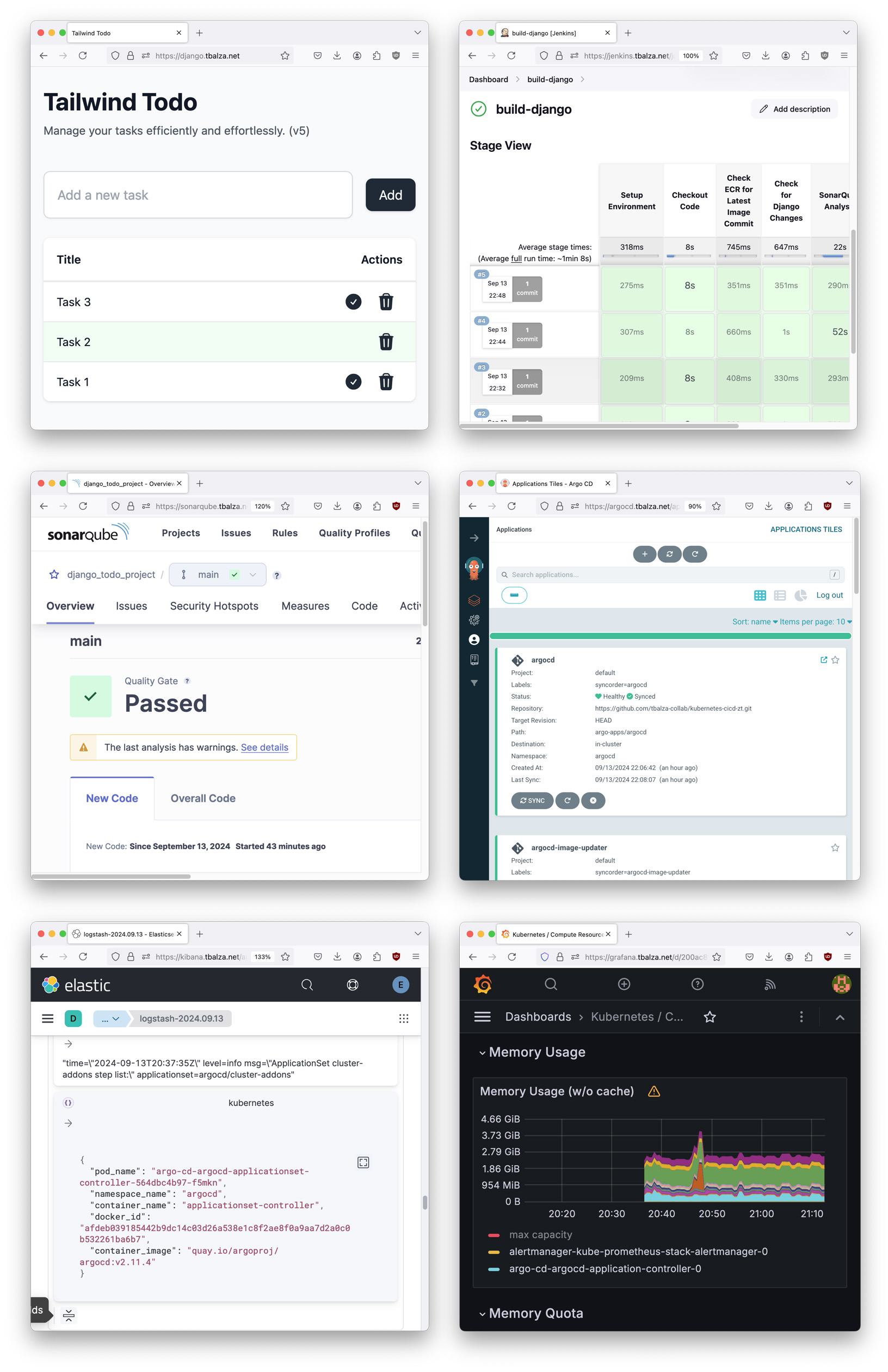
Each component with a web UI will automatically receive its own dynamic CNAME:
- django.yourdomain.com
- argocd.yourdomain.com
- sonarqube.yourdomain.com
- jenkins.yourdomain.com
- kibana.yourdomain.com
- grafana.yourdomain.com
and will be served behind an Application Load Balancer with a configured TLS certificate.
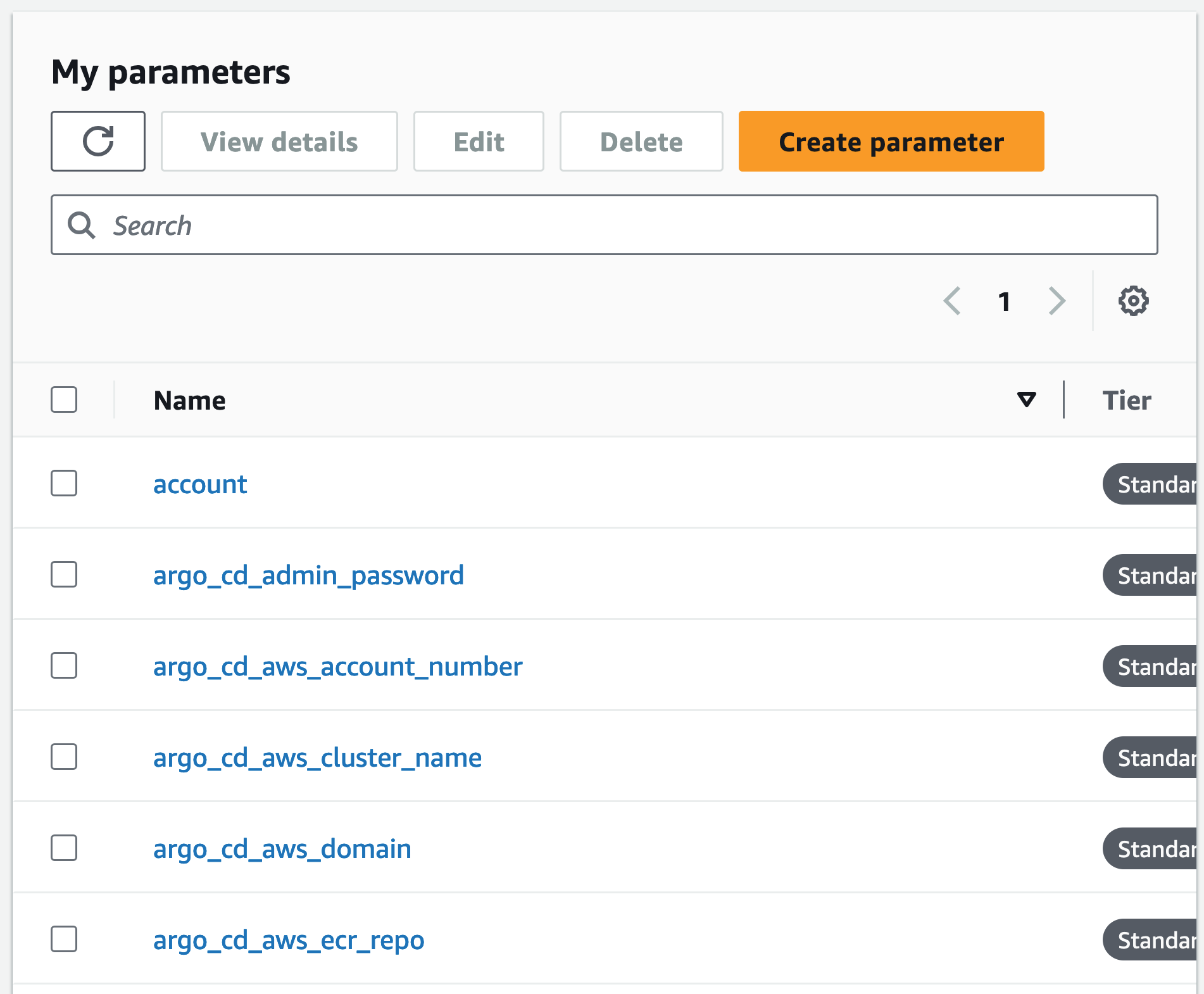
Credentials are dynamically generated and accessible through SSM Parameter Store.
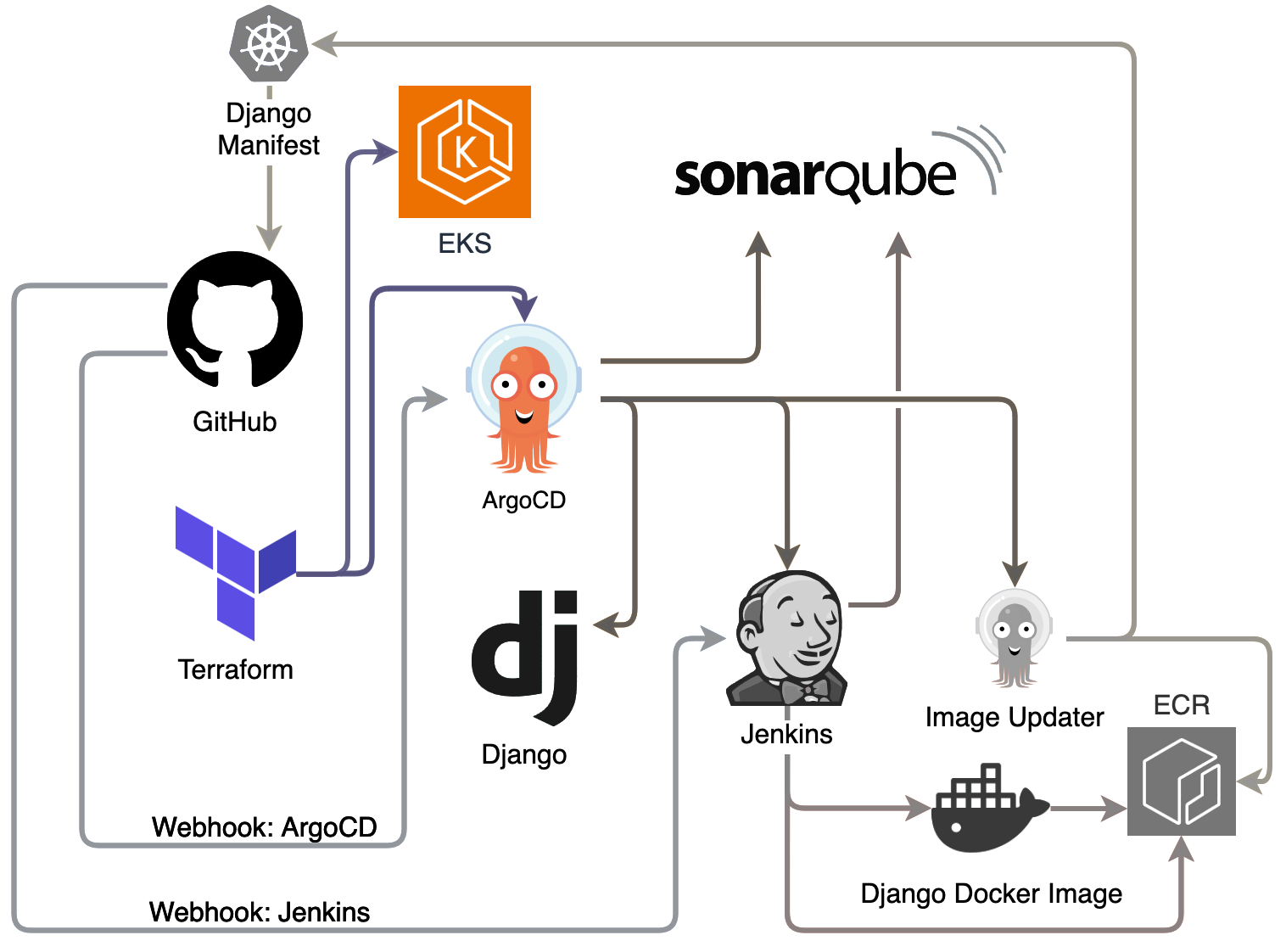
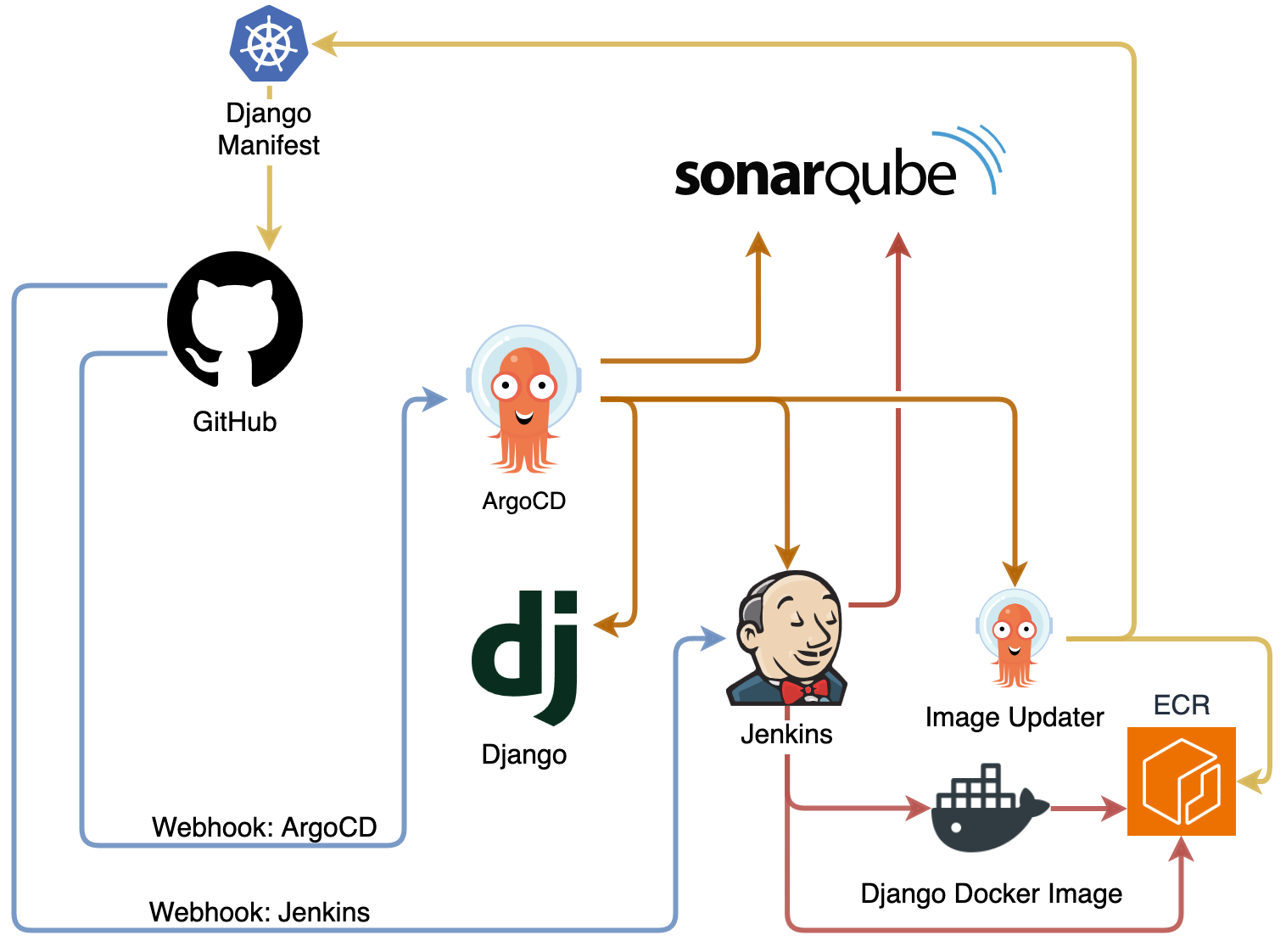
Once operational, any approved modifications to the Django app will automatically trigger the CI/CD pipeline (pictured in the diagram above), and new updates will be readily accessible via the generated subdomain.
Tooling Overview
EKS: (Kubernetes Service) Amazon’s managed container service to run and scale Kubernetes applications in the cloud without having to manage the underlying control plane.
Terraform: (IaC) A declarative infrastructure as code tool that allows you to efficiently build, change, and version infrastructure.
ECR: (Artifact Repo) Amazon’s Docker container registry that integrates with EKS allows you to store, manage, and deploy container images in this scenario.
Jenkins: (CI) A modular automation server that, in this case, builds, tests, and pushes container images to ECR.
ArgoCD: (CD) A declarative, GitOps continuous delivery tool that automates the deployment of desired application states in the Kubernetes clusters.
Elasticsearch: (Observability-Logs) A search engine used to index and analyze logs generated by applications and infrastructure. The installed stack has Kibana which provides the UI, and FluentBit which collects and transforms logs from the cluster resources.
Prometheus: (Observability-Metrics) A comprehensive toolkit that is well-suited for monitoring Kubernetes environments. The installed stack includes Grafana which allows for interactive visualization of the metrics.
Sonarqube: (DevSecOps-Static Code Analysis) An automated code review tool to detect bugs and vulnerabilities in your code. It integrates with existing Jenkins at build time to provide insights into code quality and security risks.
Django: (Main App) A high-level Python Web framework that encourages rapid development and clean, pragmatic design. It’s the main or customer-facing demo application running in the Kubernetes cluster.
Proof of Concept
DevOps integrates development and operations to enhance efficiency and reliability using IaC and GitOps practices. At the same it time promotes a space where developers can stay flexible exploring new ideas, while staying aligned with budgets and business strategies.
Adapting to this balanced environment requires fostering collaboration from key stakeholders, including management and developers.
This collaboration effort is often aided by demonstrating the practical benefits of DevOps through Proofs of Concept that align with business goals, and improve software quality without slowing things down.
Zero-Touch Setup
A Zero-Touch approach seeks to automate infrastructure provisioning and code deployment, all without requiring any manual interaction among the intermediate steps.
Fundamentally this approach is the opposite of ‘ClickOps’, where configurations are manually executed by navigating, copy/pasting and clicking through consoles and user interfaces.
In this project, data that can’t be directly baked into files (such as database endpoints generated by terraform during the provisioning process, and API keys generated during the deployment process) still exist in the code, but as abstractions that make use of tools such as External Secrets Operator to be correctly interpreted by the whole system.
This bridges the information flow gap between IaC and Gitops tasks, allowing absolutely all configuration elements to exist in the codebase. This is one of the patterns used in this PoC that eliminates the need for manual intervention while spinning up the cluster and its resources.
Getting started
To test this out on your own, follow the step-by-step instructions in the GitHub repository which cover everything that’s necessary to get started, like installing CLI tools and configuring the required credentials required for the project tools to interact with AWS, GitHub, and Cloudflare.
Provisioning Stage
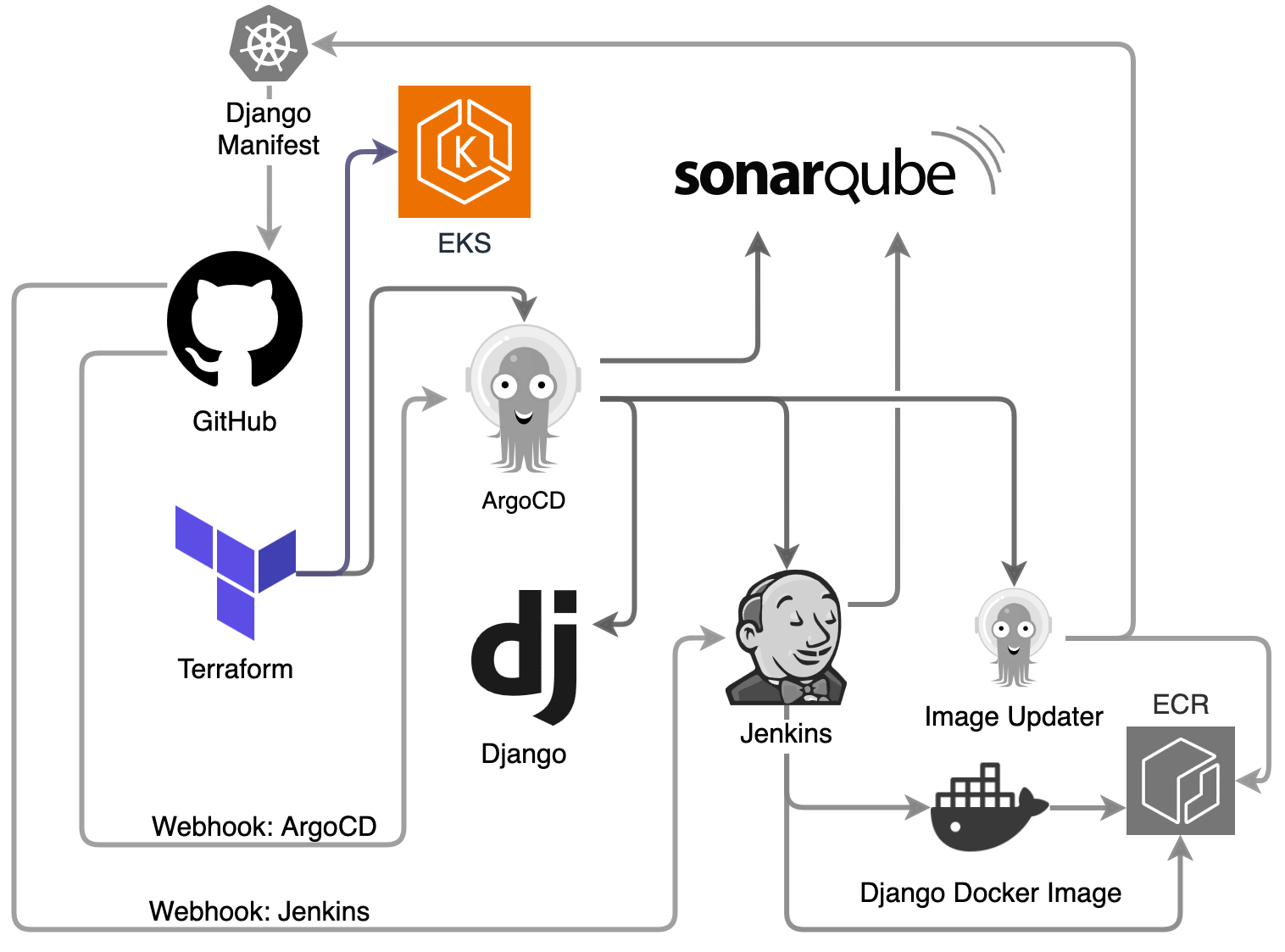
Spinning up the Initial Infrastructure with Terraform
┌── argo-apps # Deployment Stage Addons/Apps
│ ├── argocd
│ ├── argocd-image-updater
│ ├── django
│ ├── eck-stack
│ ├── fluent
│ ├── jenkins
│ ├── prometheus
│ └── sonarqube
├── django-todo # Main App Developement
└── terraform
├── 01-eks-cluster # Terraform Infra Provisioning Stage
└── 02-argocd # Terraform ArgoCD Boostrap Stage
The highlighted lines in the project’s directory structure above show what will run first to initiate the first stage towards spinning up a full Kubernetes cluster with its CI/CD pipeline.
This project uses third-party Terraform modules like the AWS EKS module to streamline infrastructure provisioning. These modules come with robust documentation and supported community-tested practices that in many cases can simplify management.
Executing terraform apply -auto-approve from within the /terraform/01-eks-cluster/ directory, will provision the EKS cluster with Node Groups, Access Entries, and resources like IAM Policies/Roles/Security Groups, ACM, VPC, RDS, SSM, Application Load Balancer, and ECR.
Deploying Core Addons
resource "helm_release" "aws_load_balancer_controller" {
name = "aws-load-balancer-controller"
repository = "https://aws.github.io/eks-charts"
chart = "aws-load-balancer-controller"
namespace = "kube-system"
version = "1.8.1" # (Chart 1.8.1, LBC 2.8.1)
set {
name = "serviceAccount.annotations.eks\\.amazonaws\\.com/role-arn" #
value = module.aws_load_balancer_controller_irsa_role.iam_role_arn
}
values = [
<<-EOF
nodeSelector:
role: "ci-cd"
EOF
]
}
Using the AWS EKS module and the helm provider, Terraform will also deploy the cluster’s core addons (CoreDNS, Kube-Proxy, VPC-CNI, EBS CSI Driver, AWS Load Balancer Controller, ExternalDNS, External Secrets Operator).
These are addons that don’t change that often (compared to the lifecycle of the main app and CI/CD tools), and that need to be in place before ArgoCD is deployed. While managing deployment via Terraform can be cumbersome down the line, setting these core addons at this stage strikes an acceptable balance with practicality and operability.
Populating SSM Parameter Store
###############################################################################
# RDS - sonarqube
###############################################################################
resource "random_password" "sonarqube_database_password" {
length = 28
special = true
override_special = "!#$%&'()+,-.=?^_~" # special character whitelist
}
At this stage data that needs to be accessed by ArgoCD such as RDS endpoints and passwords will be generated.
| |
module "ssm-parameter" {
source = "terraform-aws-modules/ssm-parameter/aws"
version = "1.1.1"
for_each = local.parameters
name = try(each.value.name, each.key)
}
And populated to the SSM Parameter Store, that will be used by External Secrets Operator later on.
ACM and Cloudflare
Since ALB cannot readily interface with cert-manager (at the time of writing) and this blog’s TLD is already running GitHub pages, I decided to go with ACM and Cloudflare.
module "acm" {
source = "terraform-aws-modules/acm/aws"
version = "5.0.1"
# ACM cert for subdomains only
domain_name = "*.${local.domain}" # only for subdomains of *.tbalza.net, TLD is not included by default
zone_id = var.CFL_ZONE_ID
validation_method = "DNS"
validation_record_fqdns = cloudflare_record.validation[*].hostname
wait_for_validation = true
create_route53_records = false
}
The ACM module creates a wildcard certificate, that will be used when ExternalDNS dynamically creates the subdomains for the CI/CD addons and the main app.
provider "cloudflare" {
api_token = var.CFL_API_TOKEN
}
# Validate generated ACM cert by creating validation domain record
resource "cloudflare_record" "validation" {
count = length(module.acm.distinct_domain_names)
zone_id = var.CFL_ZONE_ID
name = element(module.acm.validation_domains, count.index)["resource_record_name"]
type = element(module.acm.validation_domains, count.index)["resource_record_type"]
value = trimsuffix(element(module.acm.validation_domains, count.index)["resource_record_value"], ".") # ensure no trailing periods that could disrupt DNS record creation
ttl = 60
proxied = false
allow_overwrite = true
}
Using Cloudflare’s provider, Terraform is able to generate the CNAME record that ACM requires in order to validate the certificate.
CFL_API_TOKEN = "your-cloudflare-token"
CFL_ZONE_ID = "your-cloudflare-zoneid"
ARGOCD_GITHUB_TOKEN = "your-github-token"
ARGOCD_GITHUB_USER = "your-github-user"
The GitHub repo readme includes instructions and how to generate the necessary API keys, and have Terraform use them via terraform.tfvars without committing secrets to the repo with .gitignore
This whole initial provisioning cycle takes about ~25 minutes to complete.
Bootstrapping Stage
Separating Infra and App State Files
└── terraform
├── 01-eks-cluster # Terraform Infra Provisioning Stage
│ └── terraform.tfstate
└── 02-argocd # Terraform ArgoCD Boostrap Stage
└── deploy_argocd.tf
While installing core addons with Terraform can be an acceptable compromise, main application deployment should definitely be separated from infrastructure.
Applications like ArgoCD or Karpenter will create AWS resources outside of Terraform’s purview. Separating the bootstrapping stage into its own state file prevents many issues down the line. One example is that it allows for resources on the cluster to be destroyed before destroying the cluster itself.
data "terraform_remote_state" "eks" {
backend = "local" # Pending remote set up to enable collaboration, state locking etc.
config = {
path = "${path.module}/../01-eks-cluster/terraform.tfstate"
}
}
provider "helm" {
kubernetes {
host = data.terraform_remote_state.eks.outputs.cluster_endpoint
cluster_ca_certificate = base64decode(data.terraform_remote_state.eks.outputs.cluster_certificate_authority_data)
exec {
api_version = "client.authentication.k8s.io/v1beta1" # /v1alpha1"
args = ["eks", "get-token", "--cluster-name", data.terraform_remote_state.eks.outputs.cluster_name]
command = "aws"
}
}
}
Using the terraform_remote_state Data Source you can dynamically reference the infra state file outputs (in /01-eks-cluster/terraform.tfstate) to keep crucial information in sync and avoid manual data entry.
Bootstrapping ArgoCD
┌── argo-apps
│ ├── argocd
│ │ ├── kustomization.yaml
│ │ └── values.yaml
│ ├── argocd-image-updater
│ ├── django
│ ├── eck-stack
│ ├── fluent
│ ├── jenkins
│ ├── prometheus
│ └── sonarqube
├── django-todo
└── terraform
├── 01-eks-cluster
└── 02-argocd
└── deploy_argocd.tf
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
helmCharts:
- name: argo-cd
repo: https://argoproj.github.io/argo-helm
version: 7.3.4
releaseName: argo-cd
namespace: argocd
valuesFile: values.yaml
locals {
argocd_config = yamldecode(file("${path.module}/../../argo-apps/argocd/kustomization.yaml"))
argocd_helm_chart = local.argocd_config.helmCharts[0] # Access the first (or only) element in the list
}
resource "helm_release" "argo_cd" {
name = local.argocd_helm_chart.name
repository = local.argocd_helm_chart.repo
chart = local.argocd_helm_chart.releaseName
version = local.argocd_helm_chart.version
namespace = local.argocd_helm_chart.namespace
create_namespace = true
values = [file("${path.module}/../../argo-apps/argocd/values.yaml")]
}
Additionally files outside Terraform’s directory can also be referenced, so that the helm resource’s values such as chart version and additional values.yaml overrides always point to the latest version, and the bootstrapping module does not have to be edited.
ApplicationSet
resource "kubectl_manifest" "example_applicationset" {
yaml_body = file("${path.module}/../../argo-apps/argocd/applicationset.yaml")
}
Applying the ApplicationSet is the last step Terraform will perform. This will make ArgoCD deploy the main app and the CI/CD addons.
Deployment Stage
ApplicationSet II
┌── argo-apps
│ ├── argocd
│ │ ├── applicationset.yaml
│ │ ├── kustomization.yaml
│ ├── argocd-image-updater
│ │ ├── kustomization.yaml
│ ├── django
│ │ ├── kustomization.yaml
│ ├── eck-stack
│ │ ├── elastic
│ │ │ ├── kustomization.yaml
│ │ ├── kustomization.yaml
│ ├── fluent
│ │ ├── kustomization.yaml
│ ├── jenkins
│ │ ├── kustomization.yaml
│ ├── prometheus
│ │ ├── kustomization.yaml
│ └── sonarqube
│ ├── kustomization.yaml
├── django-todo
└── terraform
After the first stage succeeds, ArgoCD will “take over” and deploy and manage a fully configured CI/CD pipeline with Sonarqube, Jenkins, ArgoCD Image Updater, Django, ElasticSearch, Fluentbit, Kibana, Prometheus and Grafana.
To create each application resource dynamically, ArgoCD uses applicationtset.yaml
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: cluster-addons
namespace: argocd
spec:
goTemplate: true
goTemplateOptions: ["missingkey=error"]
generators:
- git:
repoURL: https://github.com/tbalza/kubernetes-cicd-zt.git
revision: HEAD
directories:
- path: argo-apps/*
template:
metadata:
name: '{{.path.basename}}'
spec:
project: "default"
source:
repoURL: https://github.com/tbalza/kubernetes-cicd-zt.git
targetRevision: HEAD
path: '{{.path.path}}'
destination:
server: https://kubernetes.default.svc
namespace: '{{.path.basename}}'
The ApplicationSet Git generator creates applications based on files or directory structure of a Git repository. Here, it scans all subdirectories inside argo-apps/* that contain a kustomization.yaml to create an application and assign the corresponding name and namespace using Go templating.
Kustomize and Helm
┌── argo-apps
│ ├── argocd
│ │ ├── kustomization.yaml
│ │ └── values.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: argocd # required
helmCharts:
- name: argo-cd
repo: https://argoproj.github.io/argo-helm
version: 7.3.4
releaseName: argo-cd
namespace: argocd
valuesFile: values.yaml
When the ApplicationSet loads, each kustomization.yaml from each of the app subdirectories, it will use Kustomize’s HelmChartInflationGenerator (helmCharts:) to install upstream charts with helm, using local values.yaml as overrides.
This approach has several advantages for installing well established open source tools. It simplifies management because manifests don’t need to be copied over and maintained. Pinning a version number ensures consistency in ephemeral deployments, and local values.yaml overrides provide flexibility in describing the particular configuration that suits our setup.
Additional Resources
┌── argo-apps
│ ├── argocd
│ │ ├── applicationset.yaml
│ │ ├── ingress.yaml
│ │ ├── init-container.yaml
│ │ ├── job.yaml
│ │ ├── kustomization.yaml
│ │ ├── rbac.yaml
│ │ ├── secrets2.yaml
│ │ └── values.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- job.yaml
- secrets2.yaml
- ingress.yaml
- rbac.yaml
apiVersion: external-secrets.io/v1beta1
kind: ExternalSecret
metadata:
name: argocd-secrets-global
namespace: argocd
spec:
refreshInterval: "0"
secretStoreRef:
name: argocd-secrets-global
kind: SecretStore
target:
name: argocd-secrets-global
creationPolicy: Owner
immutable: true
data:
- secretKey: ARGOCD_AWS_ACCOUNT
remoteRef:
key: argo_cd_aws_account_number
conversionStrategy: Default
decodingStrategy: None
metadataPolicy: None
On top of that, we can also apply custom manifests, that will merge seamlessly before generating the app that started from an upstream helm chart.
Configurations that are not natively supported by the upstream chart can be amended using resources or even patches get around chart definitions clashing.
│ ├── jenkins
│ │ ├── kustomization.yaml
│ │ ├── pipeline1.groovy
│ │ └── values.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
configMapGenerator:
- name: jenkins-scripts
files:
- pipeline1.groovy
JCasC:
configScripts:
job-dsl: |
jobs:
- script: >
pipelineJob('build-django') {
definition {
cps {
script(new File('/var/jenkins_home/groovy_scripts/pipeline1.groovy').text)
sandbox(true)
}
}
}
persistence:
volumes:
- name: jenkins-groovy-scripts
configMap:
name: jenkins-scripts
mounts:
- mountPath: /var/jenkins_home/groovy_scripts
name: jenkins-groovy-scripts
readOnly: true
Finally, we can also manage Kubernetes objects declaratively using configMapGenerator: which allows us, in this case, to abstract the Jenkins pipeline pipeline1.groovy from values.yaml. This keeps the main configuration lean, and allows us to version control and manage multiple complex pipelines with ease.
The end result is a streamlined way of representing the entirety of the apps configuration elements in the code base.
CMP
┌── argo-apps
│ ├── argocd
│ │ └── values.yaml
configs:
cmp:
create: true
plugins:
substitution:
generate:
command: ["/bin/sh", "-c"]
args:
- |
AVAILABLE_VARS=$(env | cut -d "=" -f 1 | awk '{print "$"$1}' | tr "\n" " ")
kustomize build --load-restrictor LoadRestrictionsNone --enable-helm | envsubst "$AVAILABLE_VARS"
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
eks.amazonaws.com/role-arn: 'arn:aws:iam::${ARGOCD_AWS_ACCOUNT}:role/ImageUpdaterRole'
name: argocd-image-updater
namespace: argocd
With a Config Management Plugin, we can enhance Argo CD’s default capabilities to include envsubst during app builds. While Kustomize allows for the inclusion of environment variables in the pods resulting from an installation, it cannot reference external variables that aren’t hardcoded in its own configuration.
To address this, we first use AVAILABLE_VARS=$(env | cut -d "=" -f 1 | awk '{print "$"$1}' | tr "\n" " ") to preload all defined ENV vars necessary for Kustomization, ensuring that other scripts’ variables are not replaced with blanks unintentionally.
Right after, the command kustomize build | envsubst "$AVAILABLE_VARS" executes for each app, dynamically substituting all pre-defined variables, such as the AWS Account Number ${ARGOCD_AWS_ACCOUNT} which would typically be static.
Although this approach might be seen as a GitOps anti-pattern, it is a practical solution in scenarios managing numerous AWS accounts, offering a balanced approach to automation.
ExternalDNS
┌── argo-apps
│ ├── argocd
│ │ └── ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: argo-cd-argocd-server
namespace: argocd
annotations:
external-dns.alpha.kubernetes.io/hostname: argocd.${ARGOCD_APP_DOMAIN}
spec:
ingressClassName: alb
rules:
- host: argocd.${ARGOCD_APP_DOMAIN}
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: argo-cd-argocd-server-grpc
port:
number: 80
- path: /
pathType: Prefix
backend:
service:
name: argo-cd-argocd-server
port:
number: 80
Each of the apps with an ingress resource has a external-dns.alpha.kubernetes.io/hostname annotation, which triggers ExternalDNS (installed in the provisioning stage), to automatically create the CNAME record corresponding to the app.
This could be templated further with Kustomize patches: for example, with a DEV environment where developers would have permissions to freely create any subdomain under *.development.${ARGOCD_APP_DOMAIN} for their testing purposes–potentially speeding up deliveries.
resource "kubectl_manifest" "cloudflare_api_key" {
yaml_body = <<-YAML
apiVersion: v1
kind: Secret
metadata:
name: cloudflare-api-token
namespace: kube-system
type: Opaque
data:
apiToken: ${base64encode(var.CFL_API_TOKEN)}
YAML
}
ExternalDNS uses the API Token defined earlier in /terraform/01-eks-cluster/setup_up_eks_cluster.tf with terraform.tfvars to interface with the Cloudflare API and create the CNAME records.
RollingSync
┌── argo-apps
│ ├── argocd
│ │ └── applicationset.yaml
│ ├── argocd-image-updater
│ ├── django
│ ├── eck-stack
│ ├── fluent
│ ├── jenkins
│ ├── prometheus
│ └── sonarqube
├── django-todo
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: cluster-addons
namespace: argocd
spec:
strategy:
type: RollingSync
rollingSync:
steps:
- matchExpressions:
- key: syncorder # Label defined in appset template:,metadata:,labels:
operator: In
values:
- argocd
- matchExpressions:
- key: syncorder
operator: In
values:
- argocd-image-updater
- sonarqube
- matchExpressions:
- key: syncorder
operator: In
values:
- django
- jenkins
- matchExpressions:
- key: syncorder
operator: In
values:
- eck-stack
- prometheus
- matchExpressions:
- key: syncorder
operator: In
values:
- fluent
template:
metadata:
name: '{{.path.basename}}'
labels:
syncorder: '{{.path.basename}}' # Label for rollingSync matchExpressions
ArgoCD’s RollingSync allows us to sequentially deploy applications without requiring user input:
- ArgoCD: is deployed first by itself, as it needs to restart with
job.yamlin order to correctly load ENV vars for CMP value substitutions in other apps. It’s able to use dynamic values initially with Terraform’s bootstrap stage. - Image Updater, SonarQube: SonarQube needs to be ready by the time the Jenkins pipeline is executed.
- Django, Jenkins: Jenkins then goes and starts to build the first image from
/django-todo, and triggers a SonarQube analysis. Django is deployed, but ArgoCD detects it doesn’t have a valid image, so it is left in a “Progressing” state, until Image Updater detects the ECR build, and modifies the new image tag in/argo-apps/django/kustomization.yaml–finally prompting ArgoCD to auto-sync Django. - Elasticsearch/Kibana, Prometheus/Grafana: Observability tools are then deployed.
- FluentBit: FluentBit needs to run after ES, in order for it to seamlessly create the index without having to restart the Elasticsearch pod.
Conclusions
We’ve covered different automation techniques using well-established open-source tools to successfully provision and deploy a complete CI/CD pipeline in a Kubernetes cluster.
These patterns align with the DevOps principles of efficiency and reliability, and also establish a single source of truth. By defining configurations in a declarative fashion and maintaining a fully automated pipeline, we can improve the speed of deliveries across environments and reduce the potential for human error.
Areas for improvement
- GitHub Actions: Automate initial project setup (not just Provisioning and Deployment)
- Security: Scope Access Entries, IAM Policies/Roles/Security Groups, SSM, to follow the principle of least privilege. Non-root Django container
- CI: Code linting. CI tests. ECR Docker Caching
- Multi Environment Setup: Implement TF workspaces with .tfvars to enable Dev, Staging, QA, Prod, environments. Implement remote state management
- SSO: Configure Single Sign On for user management, and integrate with IAM permissions
- Software Development Life Cycle: Implement examples with trunk-based development and tags
- Repo Structure: Fix long .tf files, create directories for customer facing apps along with corresponding ApplicationSets
- Crucial Addons: Install backup/DR solutions, autoscaling, cost tracking, mono repo management
Looking Ahead
For our next post, we’ll explore how implementing aspects of multi-environment setups and the software development lifecycle can make this PoC move closer to real-world production scenarios.